Book clubs can be a great way to foster learning and encourage growth on a team. They aren't always the best avenue for training, which might include:
- Formal training
- Industry events
- Presentations
- Brown bag lunches
- etc.
I always enjoyed book clubs because it gave our team a chance to discuss technical topics on a regular basis, sometimes outside of domains we were working on.
Planning a book club
If you're starting a book club for the first time, you might have to just pick a book that everyone might be interested in without specifically asking anyone. Having the desire to start a book club probably means you already know what deficiencies exist in your team, so you're better equipped to pick a book.
In that case, pick a deficiency and find a great book to study. It helps if you've read it beforehand so you know what you're getting yourself into. Book clubs need guidance and leadership during meetings to make sure learning and growth take place, and it's hard to do if the material is new to everyone.
Software books usually come in two flavors:
Examples of design books might be GoF, anything in the Fowler signature series, Pragmatic Programmer, and other books that are design/principle specific but language/technology agnostic. Technology books are filled with referential material, but not as much guidance on specific subjects like ASP.NET.
Some books I've done book clubs on are:
- Programming ASP.NET 2.0: Core Reference, Dino Esposito
- The Pragmatic Programmer, Andrew Hunt and David Thomas
- Agile Software Development: Principles, Practices and Patterns, Robert C. Martin
- Framework Design Guidelines, Cwalina and Abrams
- Working Effectively with Legacy Code, Michael Feathers
- Refactoring to Patterns, Joshua Kerievsky
As you can see, I'm heavily weighted to "Design" type books, mostly because values, principles, and practices translate well to any new technology.
Book club agenda
After we select a book, we decide on an agenda and schedule. For internal book clubs, we try to meet once a week at lunch, covering about 30-40 pages a session. We try to get each book club to end after 10-12 weeks, or about 4 months. Everyone reads all the material and discusses it at each meeting. Sometimes we skip chapters if the material isn't relevant or particularly insightful.
Here in the Austin area, we're forming an Austin-wide DDD book club to go over Evans' Domain-Driven Design book. The first thing I do in determining schedule is to break down the parts and chapters into the number of pages they take up:
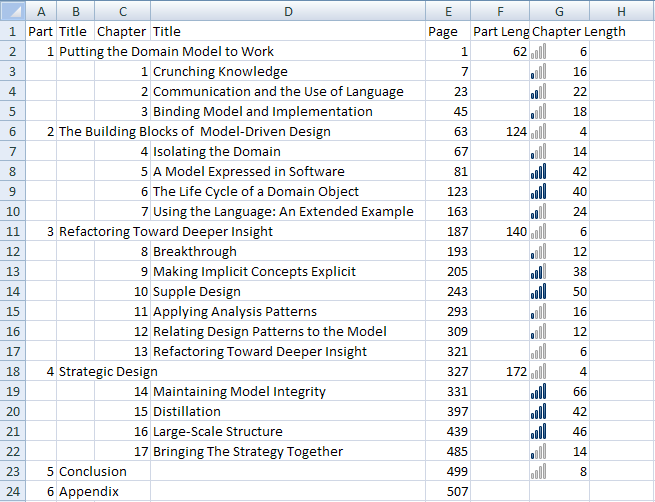
I laid out each of the chapters and noted what page they started on, then calculated the part and chapter lengths in separate columns. Since a single discussion can never cover more than 40 pages in an hour, I used conditional formatting to add bars signifying lengths of the chapter for easier planning.
Chapter length distribution seemed to be all over the place, so I created a distribution chart to see it a little more clearly:
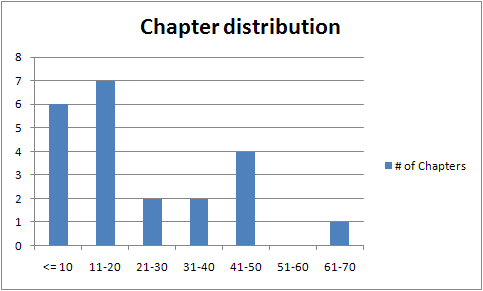
This distribution is interesting, as it shows a fairly random distribution of chapter lengths. Not Gaussian, not evenly distributed, but a whole bunch of short chapters, a few medium chapters, a few more big chapters, and one off-the chart chapter. Ideally, I'd have one 40 page chapter per session, but it doesn't always work out that way.
Suggested agendas
Sometimes, especially with the Fowler Signature Series books, the introductory chapters suggest both the important chapters and a suggested study sequence/reading sequence. This can guide the book club agenda.
In the case of the Evans book, he calls out the "most important" chapters, and says that all others can be read out of order, but are meant to be read in their entirety. We might flag some chapters as "nice to have" and put them aside, to go back to later if there's time.
The meeting
Book club meetings are meant to be fun, open, inviting, and intellectually appealing. If someone isn't engaged, they're probably on their laptop or Crack-berry, so keep an eye out for wandering minds. Asking questions tends to get everyone involved, rather than a chorus of "yeah that makes sense, I agree, echo echo echo".
If you're leading the book club, be prepared to read ahead and have a list of talking points before you go in. If anything, the book club leader is charged with creating discussion, but not leading discussion. Talking points tend to enforce focus, so discussions don't wind down tangents or social topics for too long. "OMG did you see last night's episode of 'Heroes'?" should be kept to a minimum.
Finally, be aware of your audience. If you're covering a topic new to a lot of folks, you might have to do some additional prodding to make sure everyone feels like they contributed. Nobody likes to listen to someone else's conversation for an hour (well, almost nobody).
Encouraging self-improvement
Probably the biggest benefit of book clubs and other organic training like brown bags is that they create a culture of self-improvement. Having the team engaged in book clubs, brown bags, user groups, etc. can set the bar higher when it comes to quality and pride in individual workmanship. Plus, sometimes companies pay for the lunch, so that's always good, right?


.png)

